
At cheqd, with the initiative and creativity of NYMLAB, we’re pleased to announce our leading Decentralised Identity functionality is now available across IBC, bringing DID to the Interchain at scale.
Expanding the reach of the cheqd network and our products are crucial enablers of a user-centred world of identity we are striving towards at cheqd, and we firmly believe this is only achievable through working on the two goals in parallel.
The introduction of cross-IBC proofs to the cheqd network, made possible by NYMLAB’s community-funded work and our recent upgrade to v2.0.1, is a perfect example.
NYMLAB’s core belief underpinning this project is that dApp developers looking to include SSI primitives in their product should not worry about the entire stack. They should be able to pick and choose what they need in a plug-and-play fashion.
Specifically, for this product, projects should be able to deduce which issuers’ credentials can be trusted, ensuring that the credential underpinning the Zero Knowledge presentation has not been revoked and must be verified according to custom requirements. This is what’s been built and released this week, which we’ll uncover in this blog.
First up, some key definitions. IBC stands for the Inter-Blockchain Communication Protocol (IBC), an open-source protocol to handle authentication and transport of data between blockchains. Deployed in March 2021, IBC has been adopted by 110+ sovereign chains and can be thought of as the blockchain equivalent of the internet’s TCP/IP, where it gets its name common name “the interchain”.
Tl;dr - the critical bit
Until recently, cheqd network-specific modules, such as DID (x/did) or DID-Linked Resources (x/resource), could be consumed by third-party applications over more traditional transfer protocols over HTTP, using messaging protocols such as JSON or Protobuf (Protocol Buffers).
The latest cheqd network upgrade (v2) allows this module’s functionality to be callable by other IBC-enabled chains, meaning cheqd native identity features can be used across the Interchain. Additionally, the feature set includes types for packaging smart contract messages, thus activating on-chain lookups even for smart contracts deployed on other IBC-enabled chains.
This is where NYMLAB’s vision comes into play. Currently, service providers (dApps) can use on-chain data such as addresses and NFT ownerships to provide gated services, such as access to exclusive groups and purchase opportunities, however, they cannot use credentials as these are inherently off-chain, making it challenging to offer the benefits of DID to other blockchain networks. NYMLAB believes that bringing the information proven in off-chain credentials on-chain can unlock the cheqd’s potential on-chain and across the Interchain.
To do this, zero-knowledge proofs are required, so that the data itself remains private, yet the outcome that they lead to can be enabled. NYMLAB has, therefore, built a mechanism and toolkit to enable developers to create on-chain zero-knowledge proofs for off-chain verifiable credentials, a novel approach to blending DID with the broader blockchain landscape.
Go deeper…how does it work?
In 2023, we introduced zkCreds (Anonymous Credentials) to our offerings, becoming one of the first chains to support this credential format outside of Hyperledger Indy. In doing so, we inadvertently built a module that evolved to become much more than our initial intentions.
Our DID-Linked-Resources (DLR) module allows developers to improve how resources are stored, referenced and retrieved, in line with the existing W3C DID Core standard (learn more about ‘resources’ in the context of SSI here). Beginning with the necessary resources to support AnonCreds — Credential Definitions & Schemas — we’ve found other novel use cases for them, including enabling our Credential Payments by creating the required Status Lists as DLRs, Trust Registries, Verifiable Accreditations, and now, the team at NYMLAB are using it once more to offer AnonCreds to dApps/Appchains via IBC (Interblockchain Communication Protocol)

How this could all tie together in the future
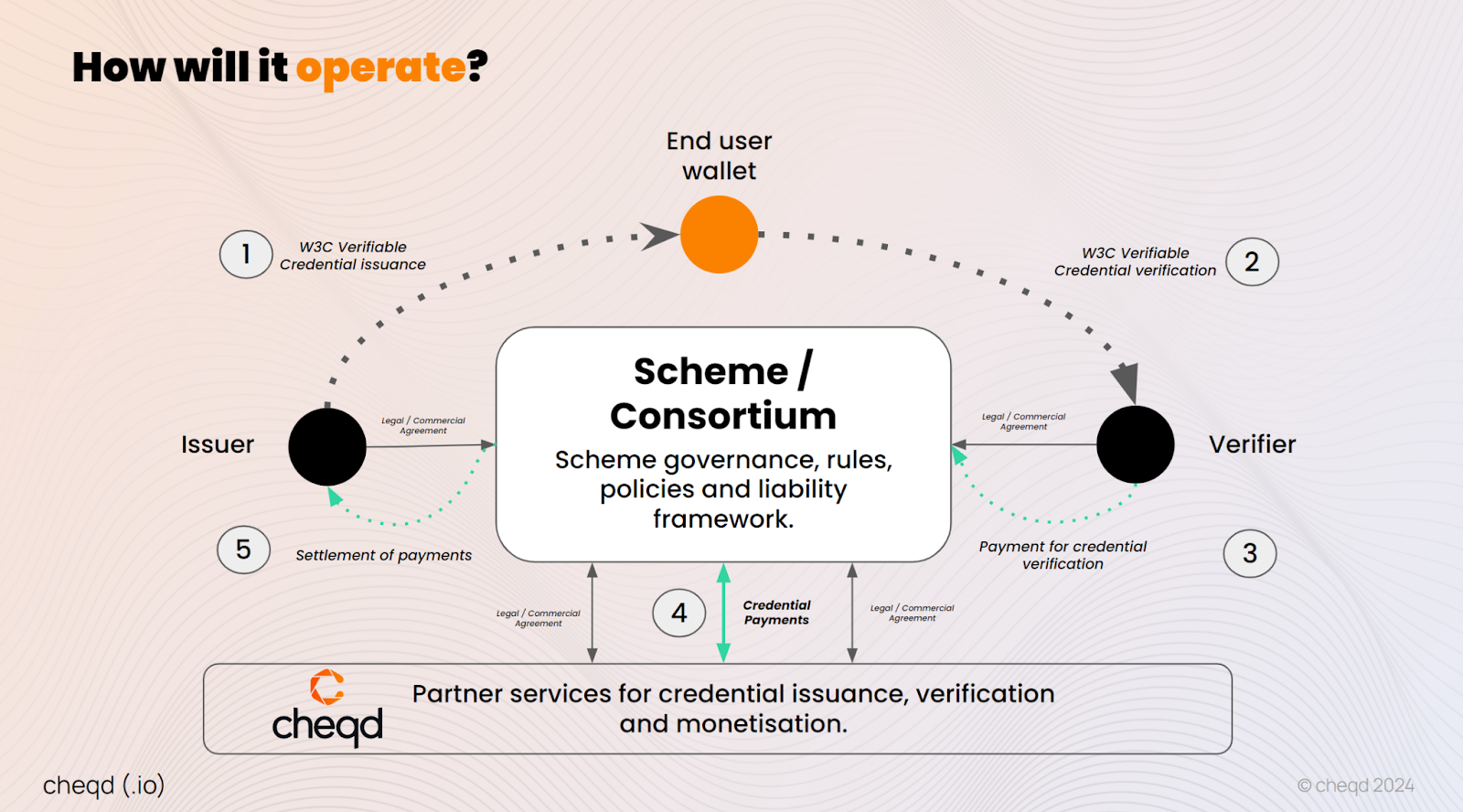
The mainnet upgrade of cheqd network to v2.x shipped a lot of the building blocks for how IBC zkProofs could combine the best of cheqd network and bring it to other Cosmos chains. This work is proposed to be carried out through future stages of community funding, but will have three critical elements: on-chain trust infrastructure, a wallet to store the credentials in, and smart contracts that can verify these zkProofs
- Trust infrastructure on cheqd network: cheqd network provides the DID and DID-Linked Resource (DLR) functionality, where issuers can anchor trusted data as they do today.
- A smart contract framework to verify/consume on-chain zkProofs: In this Stage 1 development, this was accomplished using NYMLAB’s AVIDA (Atomic Verification of Identity for Decentralised Applications), which used DID-Linked Resources published on cheqd network. AVIDA provides users the ability to create a privacy-preserving zkProof with self-derived binding between the proof presentation, their smart contract account and their Passkey credentials through AnonCreds Linked Secrets. dApps that want to utilise zkProofs can request proof presentation through their UI as part of the user’s transactions to be signed and broadcasted on-chain. After the zkProof is shared, dApps can verify the zkProof presentation using AVIDA AnonCreds Verifier, a CosmWasm contract deployable on any Cosmos SDK chain that supports CosmWasm that provides the core verification logic for dApps. This CosmWasm contract can be customised to the needs of the dApp based on their requirements, e.g., what are the trusted issuer DIDs, revocation checks and required selectively disclosure attributes.
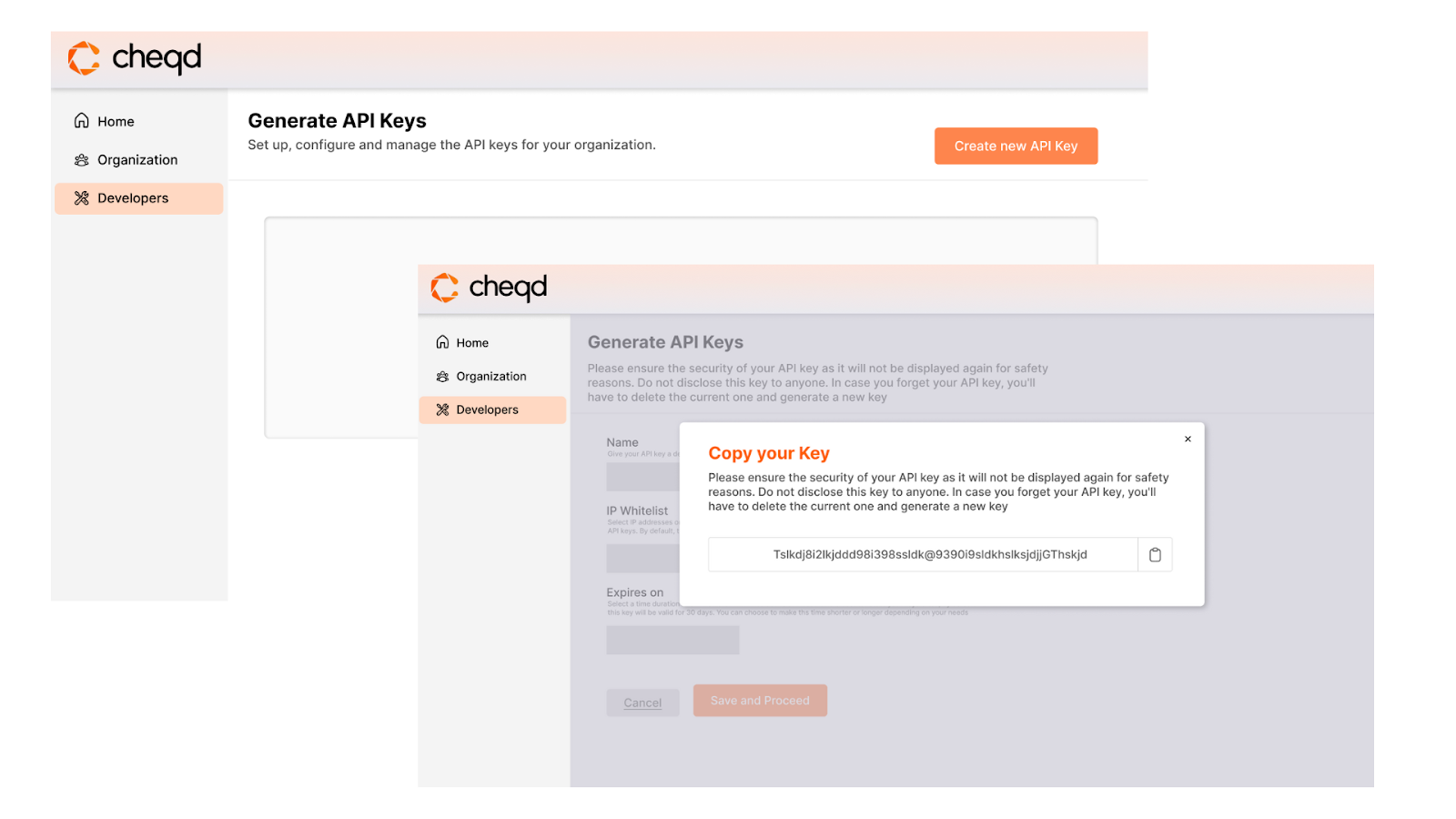
- A wallet to generate zkProofs from: In the current code developed for testing, this was NYMLAB’s Vectis wallet, which was built to combine non-custodial crypto and SSI wallets and is extensible with plugins (Passkey authentication, automation, account recovery, etc). In theory, this wallet could be Creds.xyz or any other wallet that is capable of interacting with the cheqd ledger.
In this community grant, NYMLAB adds IBC interfaces for dApps to verify presentations with issuers committed data (expanding cheqd resource usage by other chains).
Use Cases: Bringing the Code to Life
We’re looking at three initial directions for how this can be applied in practice:
- Verifiable AI: A range of different use cases for “verifiable AI” (vAI) such as Content Credentials against deepfakes, and credentials for data for AI/ML training and trained models require ZKProofs/credentials that are persistently on-chain and can be verified using on-chain smart contracts.
- Interchain ID/KYC: A ZKproof of a KYC credential issued by a cheqd DID, consumable via another AppChain (KYC-4-IBC). The powerful differentiator here is the ability with our network to either have “full KYC” credentials (with personal details) that are shared on an extremely selective basis by the use as well as “basic/zkKYC” where proofs are consumable by other Cosmos chains and dApps.
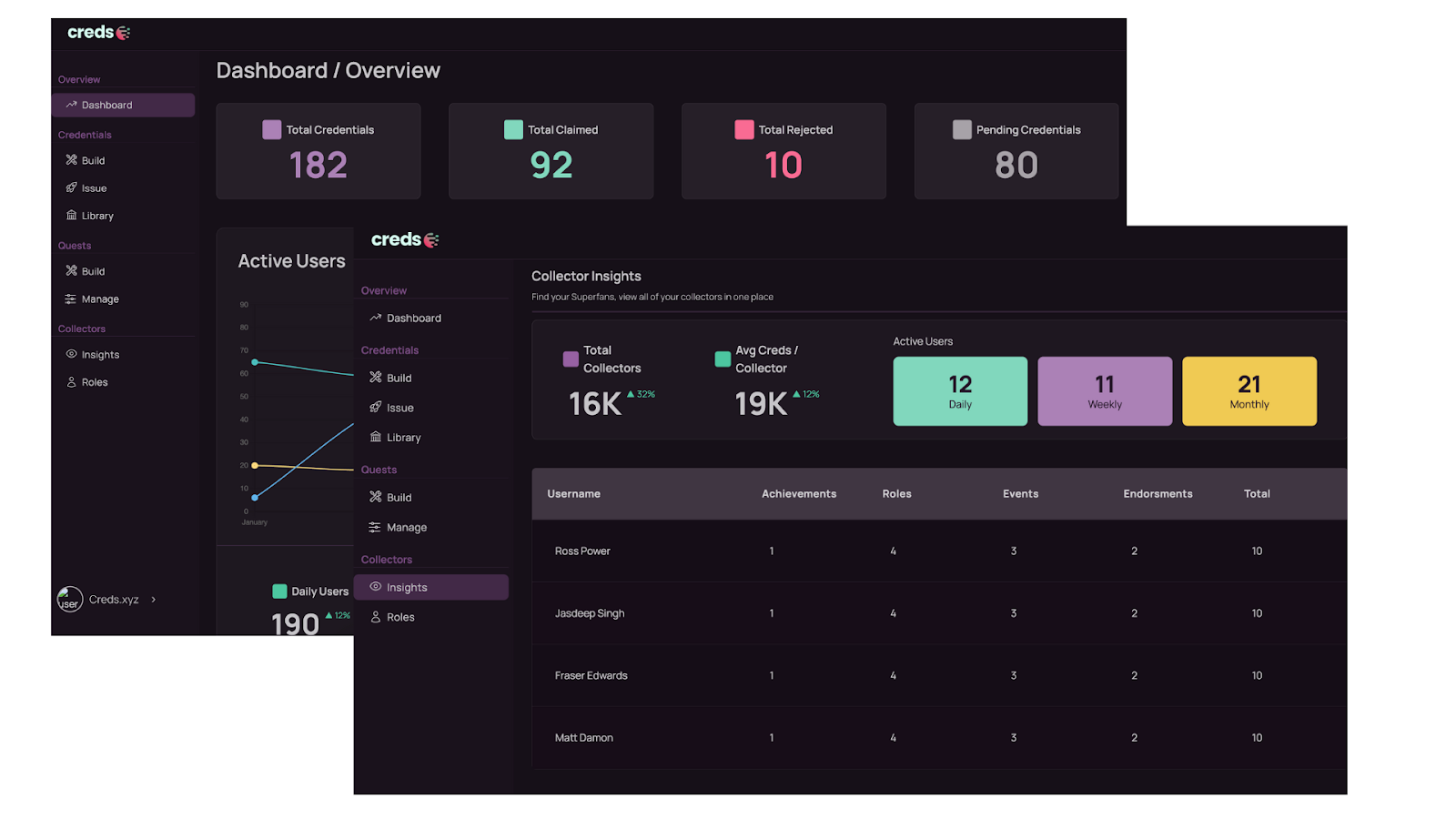
- Creds-gated Governance: Using a blend of off-chain reputation credentials and on-chain zkProofs, held by Creds.xyz Collectors to gate access to voting and/or proposing a vote in popular Cosmos governance tools
Next Steps
We’re continuing to work with the NYMLAB to bring this work to life. As a reminder of this community-funded project, the development was broken down into three stages within Prop 31.
Stage 1, completed and now distributed, included adding the ability to publish ZKproof as a DID-Linked Resource. Of the total amount allocated for this project — 45,000 EUR — 27,500 EUR has been paid to NYMLAB across two transfers (10,000 EUR at the start of the project, + 17,500 on completion).With these features now implemented and available on the cheqd network, our focus shifts towards creating an accessible developer experience.
Stage 2 will see the development of a Command Line Interface (CLI) allowing developers to jump into the code and start playing around with creating ZKproofs in seconds. This stage also includes developing and automating smart contracts that consume the proofs and verify them across IBC, the outcome being a fully functioning demonstration for issuers, verifiers, dApps and holders interacting on separate chains with cheqd’s resources. We’re also exploring running a hackathon once the CLI tools are available to encourage developers to experiment with what’s on offer.
Stage 3 wraps up the project, with all tooling open-sourced and tutorials plus extensive documentation published and available to all.
If this project is of interest, reach out to us directly, either on X (@rosspower), Telegram (ross_power) or via email ([email protected]).





















 It is likely over the coming years that we will see a ‘
It is likely over the coming years that we will see a ‘