
Announcing the launch of first-of-its-kind Credential Payments
Payment Rails are live! 🎉🥳 cheqd has built the first-of-its-kind mechanism for payments to verify digital credentials and credential status. This incentivises companies to begin adopting credential-based technologies and standards, by providing a clear commercial model for giving individuals self-sovereign control of their data.
Credential Payments is available to use through a set of easily consumable APIs within our Software as a Service offering: cheqd Studio.
Sign up for your account and get started. Create your first chargeable credential in a few clicks or lines of code using our suite of tutorials and guides.
Credential Payments solve the Chicken-and-Egg Problem
There has been a consistent cold start problem for digital credential ecosystems where organisations do not see a clear commercial model or revenue opportunity to justify the switch up costs to credential-based technologies. This is because the perceived value in Verifiable Credentials is the costs saved when there is a significant amount in circulation (the chicken🐔), but this cannot occur without organisations issuing credentials in the first place (the egg🥚).
Unfortunately, the benefits of credentials, prior to the point of mass adoption, provide no compelling reason for businesses to change their current data collection and retention practices until this is the case.
Since launching cheqd, our hypothesis has been that Credential Payments will be the catalyst for credential adoption, by incentivising issuers to release data back to the holder, and allowing them to set a price for trusted data checks. This thinking has since been validated by data collected by cheqd’s partners and potential customers, where 70% of respondents believed that payment rails would help drive adoption with their customers:
Results from the cheqd Product Survey in 2021
We now believe that credential ecosystems are technically mature enough to scale, especially with new regulations like eIDAS 2.0 accelerating their adoption and providing a template for interoperability. Yet, there is a barrier between the theoretical and philosophical benefits of Verifiable Credentials, and the commercial and business benefits of Verifiable Credentials. A payments or incentive layer is still required to provide a compelling reason for enterprise organisations to make the switch.
To achieve this shift, we’ve built Credential Payments into our cheqd Studio SaaS product to allow organisations to build trusted data markets easily, with simple REST APIs. This abstracts the complexity and responsibility of handling interactions with the ledger and provides a clear integration pathway for developers that are not familiar with decentralised identity standards or blockchain.
What companies see
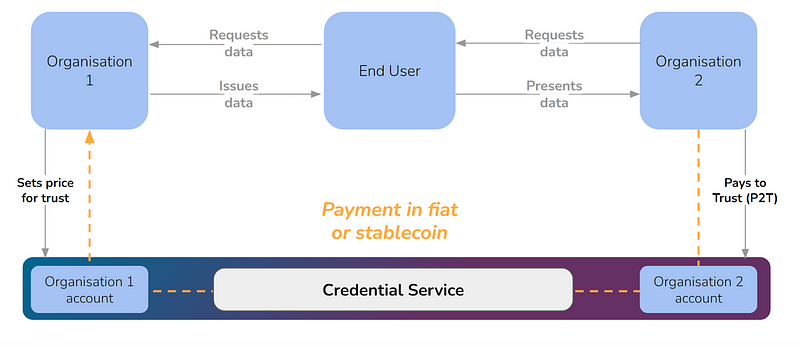
cheqd Studio customers (Issuers and Verifiers) pay a flat SaaS fee and begin simply issuing and verifying chargeable credentials. Once chargeable credentials are issued, Issuers receive recurring revenue every time the chargeable element within each credential is verified.
Verifiers can rely on a Verifiable Credential presented to them, but they can also “Pay to Trust (P2T)” in order to access extra trusted information needed to make a trust decision in the Credential. Extra trusted information may be an assessment of whether:
- The credential has been revoked or suspended.
- The Issuer belongs to a particular Trusted List or Registry.
- Customisable parameters have been met, such as governance rules and permissions set by the Issuer, for the particular credential.
This means that the payment is optional, depending on the Level of Assurance that the Verifier requires. Importantly, this payment between verifier and issuer can be in a fiat currency, a stablecoin, CBDC or other token (such as $CHEQ).
Below is a diagram showing the flow for what the customer sees:
What companies don’t see 🤓
Under the hood, Issuers are writing on-ledger transactions called Decentralised Identifiers (DIDs) and encrypted DID-Linked Resources (DLRs), such as credential Status Lists. These encrypted DLRs are “chargeable” in the sense that an Issuer is able to set a price and a time window to decrypt the DLRs in order to access the information within them.
Once the DLRs are encrypted, the decryption keys are sharded across the nodes on the network, meaning that there is no centralised entity that is able to view or access the DLR. Decryption is only able to occur once the Payment Conditions set when the DLR are met. This is privacy preserving, scalable and fully decentralised.
Unlike what companies see, the payment to decrypt the DLRs is made in cheqd network’s native token, $CHEQ, which can also be used for settlement or as an accounting mechanism to determine how much fiat or stablecoin an organisation has earned for their chargeable credentials.

$CHEQ is necessary under the hood because on-ledger resources cannot be gated using regular currency, so the $CHEQ payment to the Issuers’ address acts as a bona fide smart contract to access the data within the DLR.
You can learn more about how Credential Payments work under the hood by taking a look at our more detailed Veramo SDK tutorials here.
Understanding Payments for your use case
Credential Payments is only as powerful as the use case it supports. Notably, Credential Payments unlocks new use cases and data markets with untapped potential. This is largely centred around one idea: Reducing the Price of Trust.
Reducing the Price of Trust
Businesses are currently limited in the ability to conduct proper checks on their users and customers because it is too costly and time consuming. Identity verification checks cost upwards of $50 for comprehensive checks and between $2 to $10 for more basic checks. This prices many companies out of verifying their users because even $2 per user is too high a cost for the benefits of identity verification.
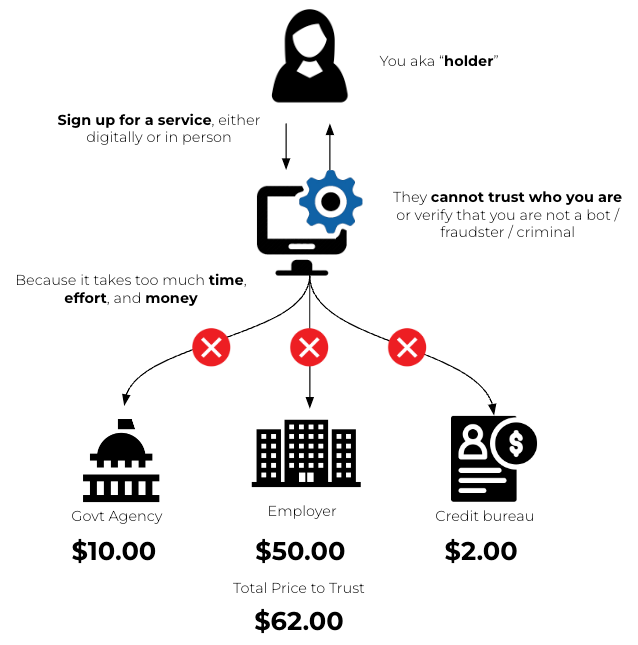
Using Verifiable Credentials and Credential Payments, the core premise is that the cost of identity checks will be greatly reduced and the time to trust someone will be near instantaneous. This unlocks new data markets, which were previously unable to verify users because it was too expensive.
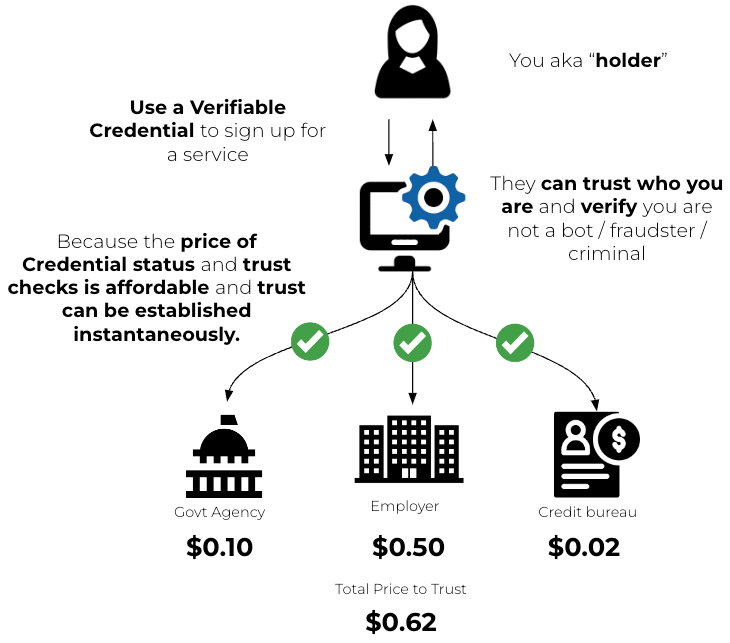
cheqd now supports paid verifications to establish whether a credential is still valid, within a defined usage period, and that it hasn’t been revoked or suspended for any reason; where, the Price of Trust is akin to a “gas fee” ⛽ within Web 3.0 payments or “transaction fee” within traditional payments.
This can be used for incentivising reliance across industries where full identity checks are currently too costly, unlocking new potential data markets across an array of use cases:
1. Accomplishments and Achievements
To trust accomplishment / achievement credentials, Verifiers need to be sure that the Issuers are legitimate. Being able to pay an Issuer to check a list of trusted Issuer identifiers gives Verifiers the ability to build higher levels of assurance in the credential presented to them, and helps to prevent fraudulent actors.
This can be used for a product like Creds where Verifiers will be able to make an optional payment to gain additional trusted information about the Cred and build higher levels of assurance in the reputation of the user.
2. DeFi
Regulations are being written and adopted worldwide for the crypto / DeFi industry with a heavy focus on enforcing KYC or qualified investor status. Credentials allow DeFi protocols to set KYC and investor acceptance requirements whilst allowing users to re-use their information seamlessly, aiming to meet regulations whilst maintaining smooth user experience.
Issuers of KYC and qualified investor credentials can now be paid for these whenever protocols need to check investor statuses, or to verify the authenticity of the KYC issuer.
3. eCommerce & retail (inc. preferences)
Credentials allow users to share relevant details instantaneously without needing to type all of them out, reducing friction. Since this data comes from a trusted source, the merchant can be comfortable that it is accurate and not fraudulent. This reduces friction and risk for the customer, potential fall-out in the checkout process for the merchant, and exposure to fraud.
Both the issuer of the original credentials and the user themselves can be paid or rewarded for providing credentials which reduce likelihood of fraud but also allow merchants or retailers to provide tailored offers.
4. Gaming & virtual / augmented reality
Credentials would allow users to port their avatars, assets, experience and reputation between or out of games seamlessly whilst easily proving their memberships or online identities to each other to prevent scamming. This means that gamers can have a much longer and deeper relationship with content like avatars since they can use them across games and platforms, increasing the volume of content available to players. Players can also flex their reputations outside of the games they have established them in.
Through cheqd, other players or games can check that a user is who they claim to be, with payments made to wherever verified the data.
5. Membership and Loyalty
Credentials are able to be used to establish that a person is a particular member or subscriber of a service or group. However, current credential expiry periods do not establish whether a user has continued to meet the terms of service of the subscription or has paid for the months’ service.
Cheqd now supports paid verification of whether a users’ membership or subscription is still valid and unsuspended. This can be used to cross-sell benefits from one subscription / membership and offer access to other services, based on a valid subscription / membership. This can also be used for incentivising new loyalty schemes, or layering a new revenue stream on top of existing membership and loyalty schemes.
Curating the "Credential Bull Market"
Verifiable Credentials are still quite an unknown concept. Mass media, for example, has focussed far more on the likes of Non-Fungible Tokens (NFTs) and Soulbound Tokens (SBTs) because of the high volatility nature of these types of technologies and their huge hype cycles within the Web 3.0 space.
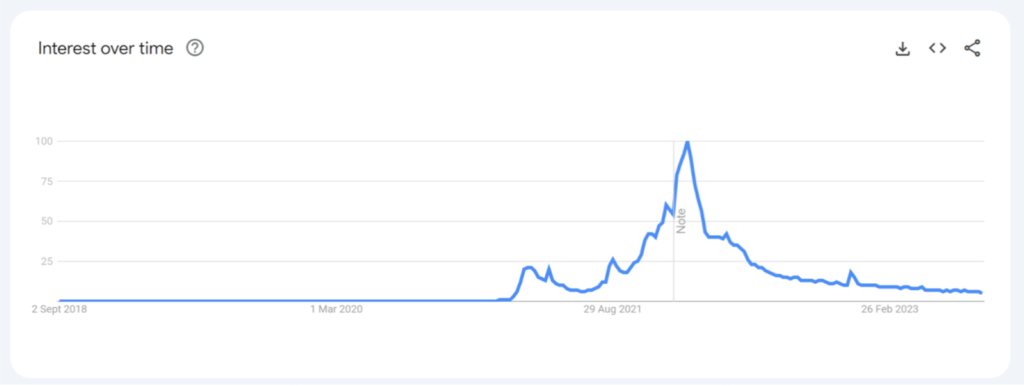
The graph below, for example, shows the significant attention that NFTs have received in the last few years, including a very large spike in the searches for the term “NFTs” in 2021. And although the interest in NFTs has steadily declined recently, the general levels of knowledge are much higher due to the boom.
Whereas, Verifiable Credentials, while not having anywhere near the same level of hype spike as NFTs, are being increasingly looked at by Regulators, Governments and enterprises as a realistic technology to solve digital trust challenges.
This is reflected in the steady increase in the amount of interest in the term “Verifiable Credentials”:
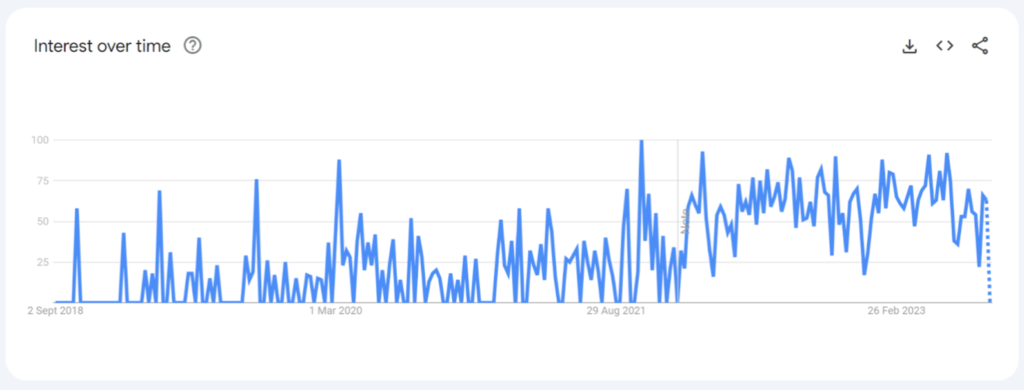
What we are beginning to see is a consistent interest in Verifiable Credentials to solve trust challenges within and between industries — but there are challenges with breaking the glass ceiling and spiking in a similar way to NFTs.
We believe that creating a financial incentive to use and issue Verifiable Credentials, we will create a “Credential Bull Market” where the volumes of Credential utility begin to spike like the 2021 NFT boom, solving the chicken and egg problem 🐣.
You can learn more about the size of the SSI market and Credential Payment opportunity here.
Looking back and stargazing
In March 2021, Fraser and Ankur announced cheqd to the world with a core idea:
“augmenting the noble goal of giving individual’s control of their data again with solid commercial reasons for companies to embrace the new paradigm. People can re-establish their privacy and companies can establish new businesses or revenue streams which have never before been possible.”
Or, in one word: incentives.
Since cheqd launched its tokenised mainnet in November 2021, we began assembling the building blocks for these “incentives” as a goal we referred to as “Payment Rails”.
First we created our Decentralised Identifier (DID) Method and the first DID on cheqd, followed by implementing our identity functionality into the Veramo SDK. Then in December 2022, we launched our innovative “DID-Linked Resources” ledger update, using this to support ZKCreds and subsequently, on-ledger forms of Credential Status Lists.
We’ve come a long way…
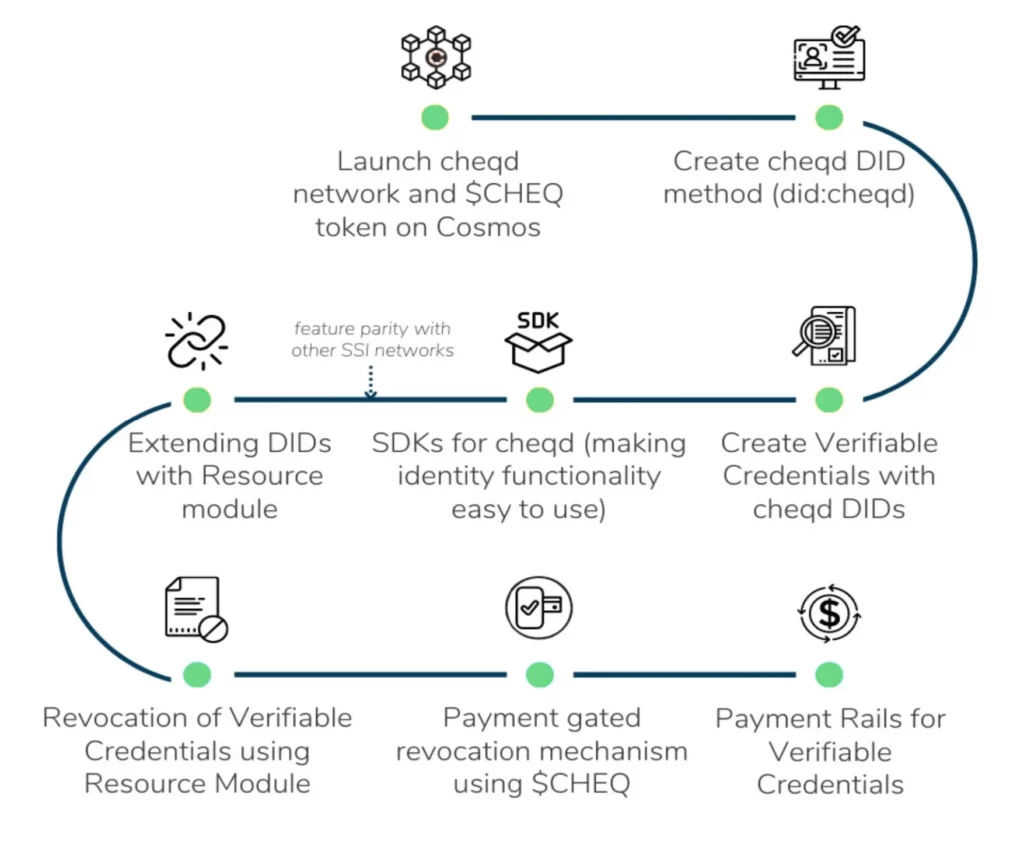
Today, we have taken each of these individual components, fit them together, and are incredibly excited to announce that we have launched an enterprise-ready Credential Payment model, which is easy to use, privacy preserving and highly scalable. 🎉🥳
Credential Payments is available to use through a set of easily consumable APIs within cheqd Studio or via a deeper integration with our Veramo SDK plugin.
P.s. if you’re a Creds user, stay tuned for Pay to Trust (P2T) Creds 🐣⌛.
Sign up for your account and get started. Create your first chargeable credential in a few clicks or lines of code.


